
平平无奇的一张图,拉高曝光就能显现另一张图?
体验站点 https://imghide.2x.nz/ 视频教程: https://www.bilibili.com/video/BV1wdh3zYESe/ 原理 首先将原图嵌入,然后将隐藏图的亮度降至极低,并以棋盘排列嵌入原图 最终生成的图片呈现一种灰色网格状 默认只能看到原图,虽然隐藏图信息仍在,但是太黑了,人眼只会把他们当作黑色像素点处理 当人为提高曝光后,原图过曝,趋于白色,丢失信息 而隐藏图被拉亮,逐渐可见 最终原图消失,而隐藏图完全显现
体验站点 https://imghide.2x.nz/ 视频教程: https://www.bilibili.com/video/BV1wdh3zYESe/ 原理 首先将原图嵌入,然后将隐藏图的亮度降至极低,并以棋盘排列嵌入原图 最终生成的图片呈现一种灰色网格状 默认只能看到原图,虽然隐藏图信息仍在,但是太黑了,人眼只会把他们当作黑色像素点处理 当人为提高曝光后,原图过曝,趋于白色,丢失信息 而隐藏图被拉亮,逐渐可见 最终原图消失,而隐藏图完全显现
前置环境准备 由于Synapse、Matrix(下文简称”矩阵“)手搓部署非常麻烦。所以请安装 1Panel面板 部署PostgreSQL 安装并创建名为 synapse 用户名也为 synapse 的数据库 前往应用商店安装 PGAdmin4 接着点击添加服务器 相关信息可以在连接信息看到 删除刚刚创建的 synapse 这个数据库 重新创建同名数据库 设置所有者(即用户名)为 synapse 将 排序规则 和 字符类型 都改为 C 部署Synapse 首先参照1Panel官方的教程去创建一个存储卷,否则安装 synapse 会失败 安装 synapse 导航到文件管理: /var/lib/docker/volumes/synapse-data/_data 你应该可以看到 编辑 homeserver.yaml ,并按需配置 server_name: "家服务器名称,比如:m.2x.nz" public_baseurl: "公共URL,比如:https://m.2x.nz" pid_file: /data/homeserver.pid serve_server_wellknown: true # 启用联邦 listeners: - port: 8008 tls: false type: http x_forwarded: true resources: - names: [client, federation] compress: false response_headers: Access-Control-Allow-Origin: "https://app.element.io" Access-Control-Allow-Methods: "GET, POST, OPTIONS" Access-Control-Allow-Headers: "Content-Type, Authorization" database: name: psycopg2 args: user: synapse password: 你的数据库密码 dbname: synapse host: 你的PostgreSQL的容器名称 cp_min: 5 cp_max: 10 log_config: "/data/my.matrix.host.log.config" media_store_path: /data/media_store registration_shared_secret: "这里的东西是随机生成的,每个人都不一样,请忽略这一块,并使用你的配置" macaroon_secret_key: "这里的东西是随机生成的,每个人都不一样,请忽略这一块,并使用你的配置" form_secret: "这里的东西是随机生成的,每个人都不一样,请忽略这一块,并使用你的配置" signing_key_path: "/data/my.matrix.host.signing.key" report_stats: false trusted_key_servers: - server_name: "matrix.org" # Github OAuth oidc_providers: - idp_id: github idp_name: Github idp_brand: "github" # optional: styling hint for clients discover: false issuer: "https://github.com/" client_id: "Ov23liaHxxYHybb0jRoZ" # TO BE FILLED client_secret: "e937f214ea7c132924ab34c76d83f4b7099d696e" # TO BE FILLED authorization_endpoint: "https://github.com/login/oauth/authorize" token_endpoint: "https://github.com/login/oauth/access_token" userinfo_endpoint: "https://api.github.com/user" scopes: ["read:user"] user_mapping_provider: config: subject_claim: "id" localpart_template: "{{ user.login }}" display_name_template: "{{ user.name }}" ### ✅ 邮件配置(确保SMTP验证正常) email: smtp_host: "你的SMTP发件服务器" smtp_port: 465 smtp_user: "你的发件邮箱" smtp_pass: "你的SMTP密码" force_tls: true notif_from: "Matrix <你的发件邮箱>" validation_token_lifetime: "5m" ### ✅ 启用注册 + 邮箱验证 + 密码找回 enable_registration: true registrations_require_3pid: - email registration_requires_token: false # 确保不强制邀请码注册(默认关闭) password_config: enabled: true ### ✅ 允许邮箱登录 login_via_existing_session: enabled: true rc_registration: per_second: 0.003 # 每秒允许的注册请求(例如:0.003 ≈ 每5分钟一次) burst_count: 1 # 同一IP地址的最大注册突发数 # 消息发送速率限制 rc_message: per_second: 0.2 # 每秒允许发送的消息数 burst_count: 10 # 突发消息缓冲区大小 # 房间加入速率限制 rc_joins: local: per_second: 0.1 # 本地用户加入房间的速率 burst_count: 10 remote: per_second: 0.01 # 远程用户加入房间的速率 burst_count: 10 # 媒体保留设置 media_retention: # 本地媒体文件的保留时间 local_media_lifetime: 90d # 远程媒体文件的保留时间(来自其他homeserver的媒体) remote_media_lifetime: 14d # 删除陈旧设备的时间 delete_stale_devices_after: 1y auto_join_rooms: - "#XXX:你的家服务器URL" # 需要自动加入的房间 按需配置,更多高级配置参阅: Homeserver Sample Config File - Synapse ...
正式开始 前往 afoim/EdgeOne_Function_PicAPI: 适用于EdgeOne边缘函数的随机图API 复制 worker.js 代码 部署到EdgeOne边缘函数 将代码开头的 R2_CONFIG 设为你自己的 var R2_CONFIG = { region: 'auto', service: 's3', accountId: '', accessKeyId: '', secretAccessKey: '', bucketName: '' }; 配置你的R2,将横屏随机图放到 ri/h 和 ri/v 。保证跟代码中的路径一样 // 根据路径确定前缀 var prefix = ''; if (pathname === '/h') { prefix = 'ri/h/'; } else if (pathname === '/v') { prefix = 'ri/v/'; } else if (pathname === '/') { 访问 /h 则展示一张横屏随机图,访问 /v 则展示一张竖屏随机图 如果需要绑定域名请设置触发规则 注意 边缘函数每月有300万次的请求数限制,暂不知道超出是否扣费
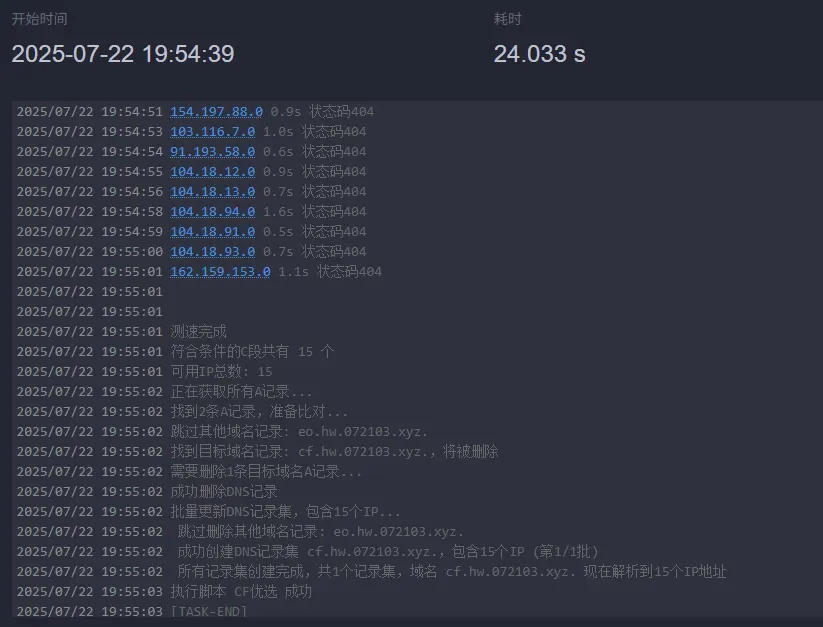
基本思路 想要做一个优选域名,我们首先需要筛选那些质量好的IP 筛选到质量好的IP后,通过各大云解析DNS厂商更新指定优选域名的DNS解析 最后,将你的域名投入使用,测试优选后效果 如何筛选到质量好的IP? 假设你要提高国内的访问质量,我们肯定需要国内的机子,如果自家有NAS就再好不过了 如果你想要三网都优选,那么只有你一台机子是不够的,需要同时拥有电信,移动,联通三网的机子去做IP筛选。如果你要做更高级的地域优选,那就…把每个省的三网机子都拿到手? 有了测试机,接下来我们就需要编写测试脚本 首先我们要知道一个CDN厂商的IP段是什么,这里以Cloudflare为例 我们搜索 Cloudflare IP段 即可找到 对于其他CDN,他们可能并没有直接在网页上公开IP,你需要自行寻找客服咨询 我们得到IP段后,接下来就是编写实际的测试逻辑 我这边仅推荐通过Curl+Resolve实现强制绑定IP访问业务域名然后看返回的状态码正不正常。 注意,这种方案及其考验您的测试机、路由器、ISP、对端服务器的性能! 但这也是最稳妥的测试方法,主播已经见过了太多TCPing 443通,https访问418或者ping得通,TCPing不通的稀奇古怪CDNIP。请保证您的测试方法筛选到的IP能正常访问到您的访问,避免您的服务宕机 线程不必拉太高,针对于Cloudflare这样有 150w IP的CDN,我们可以仅测试C段,也就是测试完 104.18.91.0 直接测试 104.18.92.0 这样可以节省时间,只需要测5000多个IP 最终,我们得到了一组优选IP 对接华为云云解析DNS 为什么推荐华为云? 无他,因为仅华为云一家支持单解析单次记录值支持50个IP、可以创建多个同名解析以及支持仅缓存DNS解析1s(TTL=1) 受益于华为云的这些功能,我们个人用户也可以做到一个域名下面绑定几万个IP(虽然IP不是越多越好) 推荐使用海外版,不需要实名认证 之后通过API文档自行折腾一下API添加DNS解析即可 后期维护 如果你要做三网优选请添加一个默认解析线路,保证您在个别线路宕机时对应线路的用户不会遇到服务宕机 每个CDN厂商的IP段可能会不定时变更,请勤查多看,及时更换失效IP 如果遇到服务异常无法得到优选IP,请不要在脚本中编写危险逻辑,如删除所有解析。这会导致大批量服务宕机 优选并不是主流做法,如果您的站点被攻击,使用自定义CNAME或者IP会导致您的CDN服务商无法为您进行IP调度,高质量IP将被持续攻击,您的CDN服务商可能会采取强制措施如:关停您的业务,封禁您的账号等操作来隔断对方的攻击。当您认为您的站点被攻击时请及时切换到官方为您分配的CNAME或IP
视频教程 https://b23.tv/E8Z34KM 正式开始 资源: https://r2.2x.nz/chevereto_4.3.6-Pro_unlock.zip (感谢宝塔开心版站长!) 使用 PHP 8.1.29 & MySQL 8.0.36 创建一个网站,然后将我们刚刚下载的ZIP上传到站点根目录并解压 你就会得到这一坨 这里开始分支!如果你是Apache请什么都不要动,它会自动检测 .htaccess 。如果你是Nginx请配置 nginx.txt 里面的伪静态规则 然后根据原 教程.txt PHP 需要 8.1 以上 需要以下PHP扩展: fileinfo imagemagick exif 如果是宝塔 还得删除 PHP 禁用函数 putenv proc_open MYSQL 需要 8.0 以上 伪静态需要使用我提供的 nginx.txt 里面的 如果你用的虚拟主机跟博主一样,也是ispmanager,请这样设置PHP 一切就绪,访问你的站点进行Chevereto的安装向导 疑难解答 如果出现问题,请尝试以管理员身份登录Chevereto,在管理员设置 -> 系统中开启调试模式。这样设置后,Chevereto在出现错误就会告诉你具体发生了什么问题 如果我连系统设置都进不去?请自行找你的PHP Error Log来分析问题 我搭建好的 https://chevereto.php.afo.im/upload 登录后查看所有图片: https://chevereto.php.afo.im/explore/images
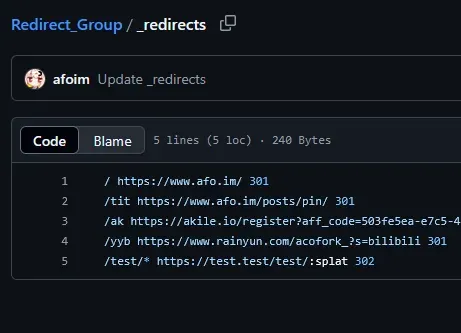
快速上手! 直接 Fork我的 仓库 。 接着将该仓库连接到Cloudflare部署Worker或Page,然后绑定你的域名 接着更改 _redirects 内的文件 例如: / https://www.afo.im/ 301 /test/* https://test.test/test/:splat 302 则意味着 访问 / 301 永久重定向到 https://www.afo.im/ 访问 /test/* 302 临时重定向到 https://test.test/test/* 已经非常强大了。而且不占用重定向规则配额也不耗费Worker请求数!
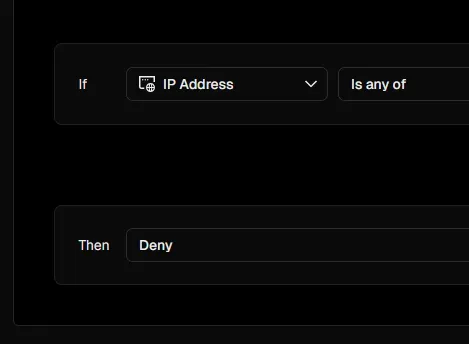
配套视频 https://www.bilibili.com/video/BV1w7GTzMEy7 获取ITDog等拨测服务的IP 因为Vercel不支持IPv6,所以我们只需要获取v4IP 如果你有VPS,直接写一个Py脚本创建一个HTTP服务器记录IP去重即可 如果你只有家里云,可以使用Cloudflare Tunnel,然后获取 CF-Connecting-IP 来曲线救国 结论,你已经获得了你要屏蔽的拨测网站的IP 创建Vercel API Token 前往 https://vercel.com/account/settings/tokens 创建一个Token 抓取防火墙创建/更新接口 前往 https://vercel.com/your-projects/fuwari/firewall 新增规则 随便写点东西然后抓包 PATCH https://vercel.com/api/v1/security/firewall/config/draft?projectId=prj_UfvbpIvawjL2eAETAiZT7hPLR8W2&teamId=team_lemndzHQNJAcTipIF6elB5Md 将主机名 vercel.com 改为 api.vercel.com 。并携带请求头 Authorization ,值为刚才获取的Token 复制刚才的响应并且稍作修改进行测试,看是否能更新成功 可以看到已经200 OK 使用Python脚本创建大批量IP拒绝规则 根据本人测试,Vercel虽然在创建规则的时候有一个 is any of 支持填入多个IP,但是单规则最多只能填写75个,所以我们需要一个Python脚本批量帮我们规划。脚本已经写好 使用: python app.py ip.txt 作用:自动获取指定TXT中的内容并将其中的所有IP添加到拒绝规则 #!/usr/bin/env python3 # -*- coding: utf-8 -*- """ Vercel防火墙规则更新脚本 用法: python vercelnoitdog.py xxx.txt """ import sys import json import requests import ipaddress from typing import List, Dict, Any # Vercel API配置 API_BASE_URL = "https://api.vercel.com/v1/security/firewall/config/draft" PROJECT_ID = "prj_UfvbpIvawjL2eAETAiZT7hPLR8W2" TEAM_ID = "team_lemndzHQNJAcTipIF6elB5Md" AUTH_TOKEN = "你的Token" RULE_ID = "rule_noitdog_eGxdcK" # 每组最大IP数量 MAX_IPS_PER_GROUP = 75 def validate_ip_or_cidr(ip_str: str) -> bool: """ 验证IP地址或CIDR格式是否有效 """ try: # 尝试解析为IP地址或网络 ipaddress.ip_address(ip_str) return True except ValueError: try: # 尝试解析为CIDR网络 ipaddress.ip_network(ip_str, strict=False) return True except ValueError: return False def read_ips_from_file(file_path: str) -> List[str]: """ 从文件中读取IP地址和CIDR网段 """ ips = [] invalid_entries = [] try: with open(file_path, 'r', encoding='utf-8') as f: for line_num, line in enumerate(f, 1): ip = line.strip() if ip and not ip.startswith('#'): # 忽略空行和注释 if validate_ip_or_cidr(ip): ips.append(ip) else: invalid_entries.append(f"第{line_num}行: {ip}") print(f"从文件 {file_path} 读取到 {len(ips)} 个有效的IP地址/CIDR网段") if invalid_entries: print(f"⚠️ 发现 {len(invalid_entries)} 个无效条目:") for entry in invalid_entries[:5]: # 只显示前5个 print(f" {entry}") if len(invalid_entries) > 5: print(f" ... 还有 {len(invalid_entries) - 5} 个无效条目") return ips except FileNotFoundError: print(f"错误: 文件 {file_path} 不存在") sys.exit(1) except Exception as e: print(f"读取文件时出错: {e}") sys.exit(1) def chunk_ips(ips: List[str], chunk_size: int = MAX_IPS_PER_GROUP) -> List[List[str]]: """ 将IP列表分组,每组最多包含指定数量的IP """ chunks = [] for i in range(0, len(ips), chunk_size): chunks.append(ips[i:i + chunk_size]) return chunks def create_condition_groups(ip_chunks: List[List[str]]) -> List[Dict[str, Any]]: """ 创建条件组,每个组包含一个IP列表 """ condition_groups = [] for ip_chunk in ip_chunks: condition_group = { "conditions": [ { "op": "inc", "type": "ip_address", "value": ip_chunk } ] } condition_groups.append(condition_group) return condition_groups def create_request_payload(condition_groups: List[Dict[str, Any]]) -> Dict[str, Any]: """ 创建请求负载 """ payload = { "action": "rules.update", "id": RULE_ID, "value": { "name": "noitdog", "active": True, "description": "", "conditionGroup": condition_groups, "action": { "mitigate": { "action": "deny", } } } } return payload def send_request(payload: Dict[str, Any]) -> bool: """ 发送PATCH请求到Vercel API """ url = f"{API_BASE_URL}?projectId={PROJECT_ID}&teamId={TEAM_ID}" headers = { "Authorization": f"Bearer {AUTH_TOKEN}", "Content-Type": "application/json" } try: print(f"发送请求到: {url}") print(f"请求数据: {json.dumps(payload, indent=2, ensure_ascii=False)}") response = requests.patch(url, headers=headers, json=payload) print(f"响应状态码: {response.status_code}") print(f"响应内容: {response.text}") if response.status_code == 200: print("✅ 请求成功") return True else: print(f"❌ 请求失败: {response.status_code} - {response.text}") return False except requests.exceptions.RequestException as e: print(f"❌ 网络请求错误: {e}") return False except Exception as e: print(f"❌ 发送请求时出错: {e}") return False def main(): """ 主函数 """ if len(sys.argv) != 2: print("用法: python vercelnoitdog.py <ip_file.txt>") print("示例: python vercelnoitdog.py ips.txt") sys.exit(1) ip_file = sys.argv[1] # 读取IP地址 ips = read_ips_from_file(ip_file) if not ips: print("❌ 没有找到有效的IP地址或CIDR网段") sys.exit(1) # 去重 unique_ips = list(set(ips)) print(f"去重后共有 {len(unique_ips)} 个唯一IP地址/CIDR网段") # 分组 ip_chunks = chunk_ips(unique_ips) print(f"IP地址被分为 {len(ip_chunks)} 组") for i, chunk in enumerate(ip_chunks, 1): print(f"第 {i} 组: {len(chunk)} 个IP/CIDR") # 创建条件组 condition_groups = create_condition_groups(ip_chunks) # 创建请求负载 payload = create_request_payload(condition_groups) # 发送请求 success = send_request(payload) if success: print("\n🎉 防火墙规则更新成功!") else: print("\n💥 防火墙规则更新失败!") sys.exit(1) if __name__ == "__main__": main() 示例ip.txt ...
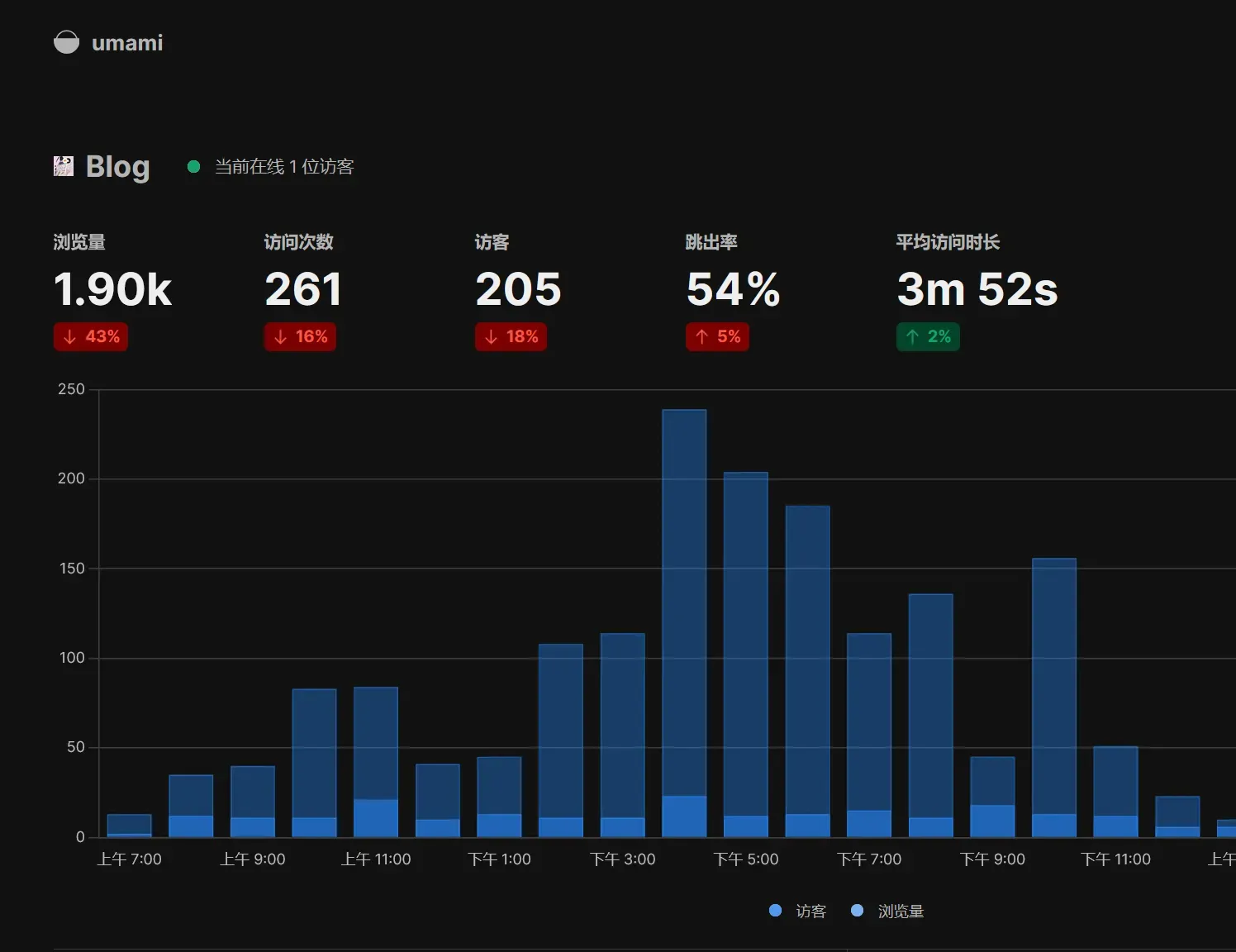
正式开始 本教程针对于Umami Cloud的上手使用,如果你需要自托管Umami请自行寻找相关文档 进入 https://umami.is/ (如果进不去请检查是否有广告拦截器拦截了Umami!!!) 点击右上角的 Sign UP 注册账号 按需填写相关信息进行注册 然后检查你的邮箱,是否收到了Umami的邮箱验证消息 点击 Login 进行登录,填入验证码 区域选择任意(选美国你的统计数据就记录在美国的服务器,选欧盟你的统计数据就记录在欧盟的服务器) 用户配置随便填写即可 继续填写你要统计的网站 将跟踪代码插入到你的网站的 <head>Umami跟踪代码</head> 中 然后我们就进入Umami控制台了 点击 View 就能看到你的网站统计啦 注:右上角可以改为中文 建议打开设置启用分享URL,这样你的用户就可以实时看到你的站点流量啦 注意事项 Umami Cloud对于免费用户限制3个站点 免费版月事件数为10w,本人博客感觉不够用,已经自建了,教程可以看我b站,没有就是没发 来拷打我
正式开始 视频教程: https://www.bilibili.com/video/BV1i53PzUEzE/ 后端部署 Github: https://github.com/MemeCrafters/meme-generator 安装依赖 pip install -U "meme_generator<0.2.0" 克隆仓库 git clone https://github.com/MemeCrafters/meme-generator 克隆额外表情仓库 git clone https://github.com/MemeCrafters/meme-generator-contrib git clone https://github.com/anyliew/meme_emoji 前往 ~/.config/meme_generator/config.toml 填入配置文件。并且填入刚刚克隆的额外表情仓库: meme_dirs [meme] load_builtin_memes = true # 是否加载内置表情包 meme_dirs = ["/root/meme-api/meme-generator-contrib/memes", "/root/meme-api/meme_emoji/emoji"] # 加载其他位置的表情包,填写文件夹路径 meme_disabled_list = [] # 禁用的表情包列表,填写表情的 `key` [resource] # 下载内置表情包图片时的资源链接,下载时选择最快的站点 resource_urls = [ "https://raw.githubusercontent.com/MemeCrafters/meme-generator/", "https://mirror.ghproxy.com/https://raw.githubusercontent.com/MemeCrafters/meme-generator/", "https://cdn.jsdelivr.net/gh/MemeCrafters/meme-generator@", "https://fastly.jsdelivr.net/gh/MemeCrafters/meme-generator@", "https://raw.gitmirror.com/MemeCrafters/meme-generator/", ] [gif] gif_max_size = 10.0 # 限制生成的 gif 文件大小,单位为 Mb gif_max_frames = 100 # 限制生成的 gif 文件帧数 [translate] baidu_trans_appid = "" # 百度翻译api相关,表情包 `dianzhongdian` 需要使用 baidu_trans_apikey = "" # 可在 百度翻译开放平台 (http://api.fanyi.baidu.com) 申请 [server] host = "127.0.0.1" # web server 监听地址 port = 2233 # web server 端口 [log] log_level = "INFO" # 日志等级 运行 ...
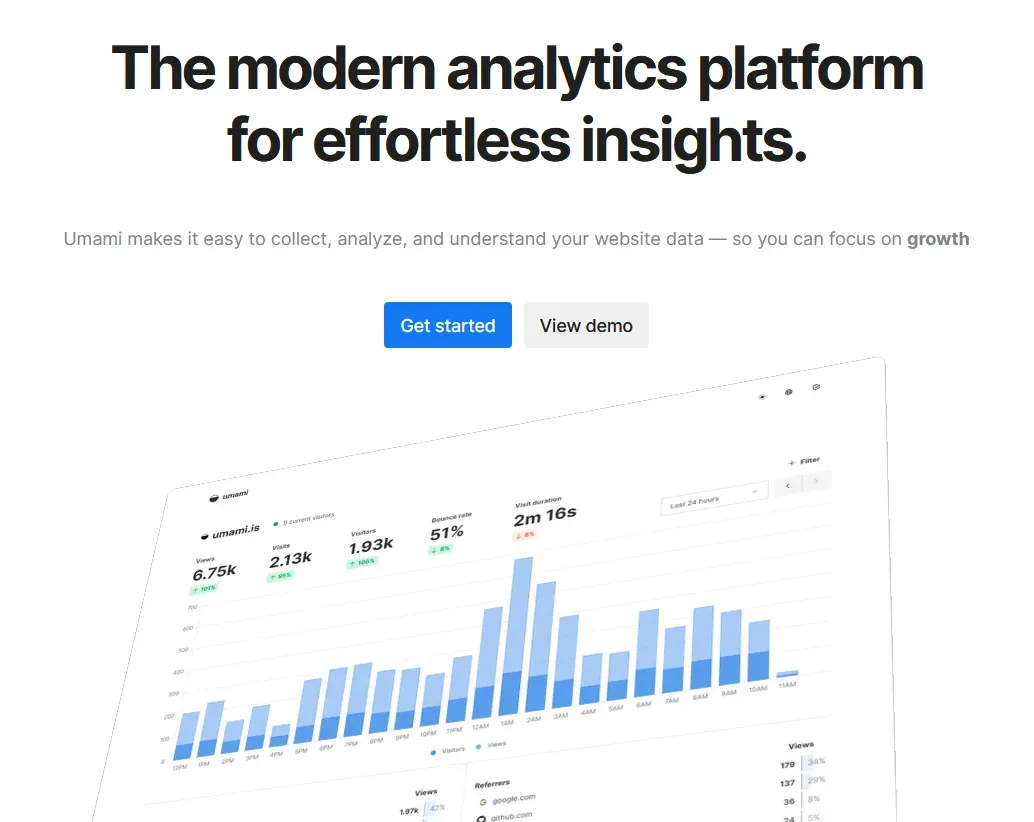
引言 如果你用过WordPress,Halo等动态博客框架,你大概会在用户视角访问博文的时候看到浏览量这个信息。 这个原理很简单,因为动态博客依赖于一个VPS,只需要让用户每次访问的时候给浏览量+1即可。 那么如果我们是静态博客呢? 我们可以依赖一些第三方服务,比如Umami Cloud。在你的静态博客的head注入一个js,这样你就可以看到你的站点分析了,类似下图 现在我们确实可以看到每个文章(即/posts/xxx)的访问量了,但是我们要如何展示给用户呢? 逆向Umami的只读页面!(新版v3) 感谢nightNya提供的方案,你是天才! 首先我们启用分享URL 注意这里的 7PoDRgCzHFTs2vWB ,每个站点都不一样 接着我们请求 https://cloud.umami.is/analytics/us/api/share/7PoDRgCzHFTs2vWB,得到 注意,这里的 us 为你创建的账号区域,美国为us,欧盟为eu { "websiteId": "a66a5fd4-98b0-4108-8606-cb7094f380ac", "token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ3ZWJzaXRlSWQiOiJhNjZhNWZkNC05OGIwLTQxMDgtODYwNi1jYjcwOTRmMzgwYWMiLCJpYXQiOjE3NTA4MDIwMzB9.X5GQT5kslh6r25sFlap4Asz1NDA7mN3kcZW8wqbrnBc" } 再接着我们请求,携带请求头 x-umami-share-token 值为上一步获得的Token https://cloud.umami.is/analytics/us/api/websites/a66a5fd4-98b0-4108-8606-cb7094f380ac/stats?startAt=0&endAt=1750805999999&unit=hour&timezone=Asia/Hong_Kong&path=eq./posts/cf-fastip/&compare=false 这里解释几个关键Params,其他的照搬 startAt:统计开始时间。Unix时间戳,我们填写为0让Umami从1970年开始统计 endAt:统计结束时间。Unix时间戳,我们可以使用 Date.now() ,即当前时间,和startAt参数联动即可实现统计总浏览量 path:要查询的路径,填写为你的文章页去除了Host的路径,如 /posts/hello 。注意!Umami会将 /posts/hello 和 /posts/hello/ 视为两个不同的路径,请注意你的博客框架是否使用 /。在v3版本中,需要使用 eq. 前缀来进行精确匹配,例如 path=eq./posts/hello/ 你会得到 { "pageviews": 1655, "visitors": 343, "visits": 411, "bounces": 183, "totaltime": 30592, "comparison": { "pageviews": 0, "visitors": 0, "visits": 0, "bounces": 0, "totaltime": 0 } } pageviews 即浏览量。 visitors 即访问人数。 Tips:浏览量记录为任意用户只要访问了则计数一次。而访问数记录不会记录单IP多次重复访问和同一时间段的多次请求不同页面 Enjoy it! ...